

For any subscription-based business model – the key to successful growth is customer retention and customer subscription. Unearthing factors that increase subscription and retention amongst customers require an acute understanding of customers’ behavior. If we can unlock the pattern in which customer interacts with the service or product, we can understand what makes them stay and subscribe. This article will explain how to use machine learning to increase the propensity of customers to subscribe.
We often have much information about the customers, but congregating them together and making sense of it is not easy. Analyzing features separately is done more often as it is easier, but it gives a minimal picture of what is happening. Machine learning algorithms allow predictive analysis based on a large number of features. If we have data from at least a million customers, we can efficiently run analysis based on 40 to 50 features, even with a simple machine learning model.
The Premise
One of our latest clients required something similar. Our client was an information technology company with a subscriber-based mobile app. Their customers went through a funnel as follows.
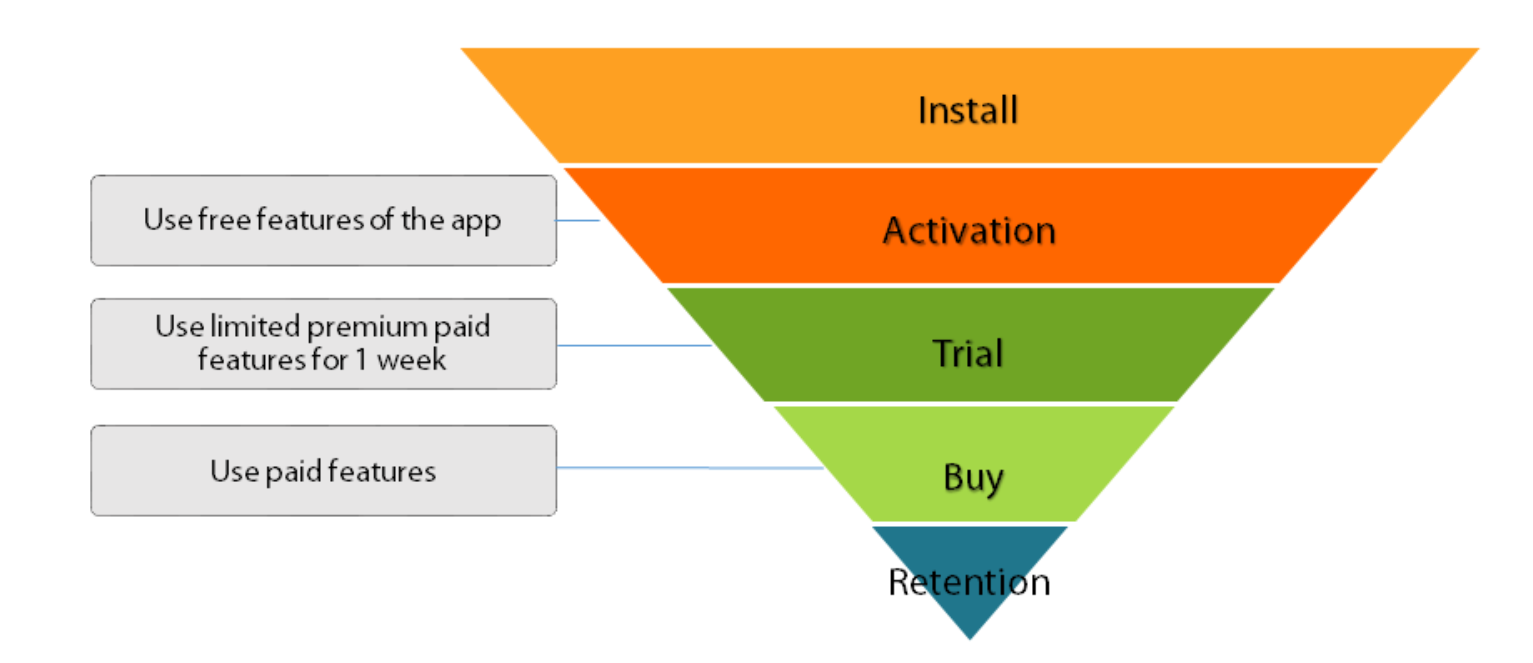
Although more than half the customers who trialed for a week also ended up subscribing for premium paid features, very few of those who registered went for trial. This meant that no matter what percentage of customers went for paid subscriptions from the week-long trial, the overall number of premium paid subscribers was still very low.
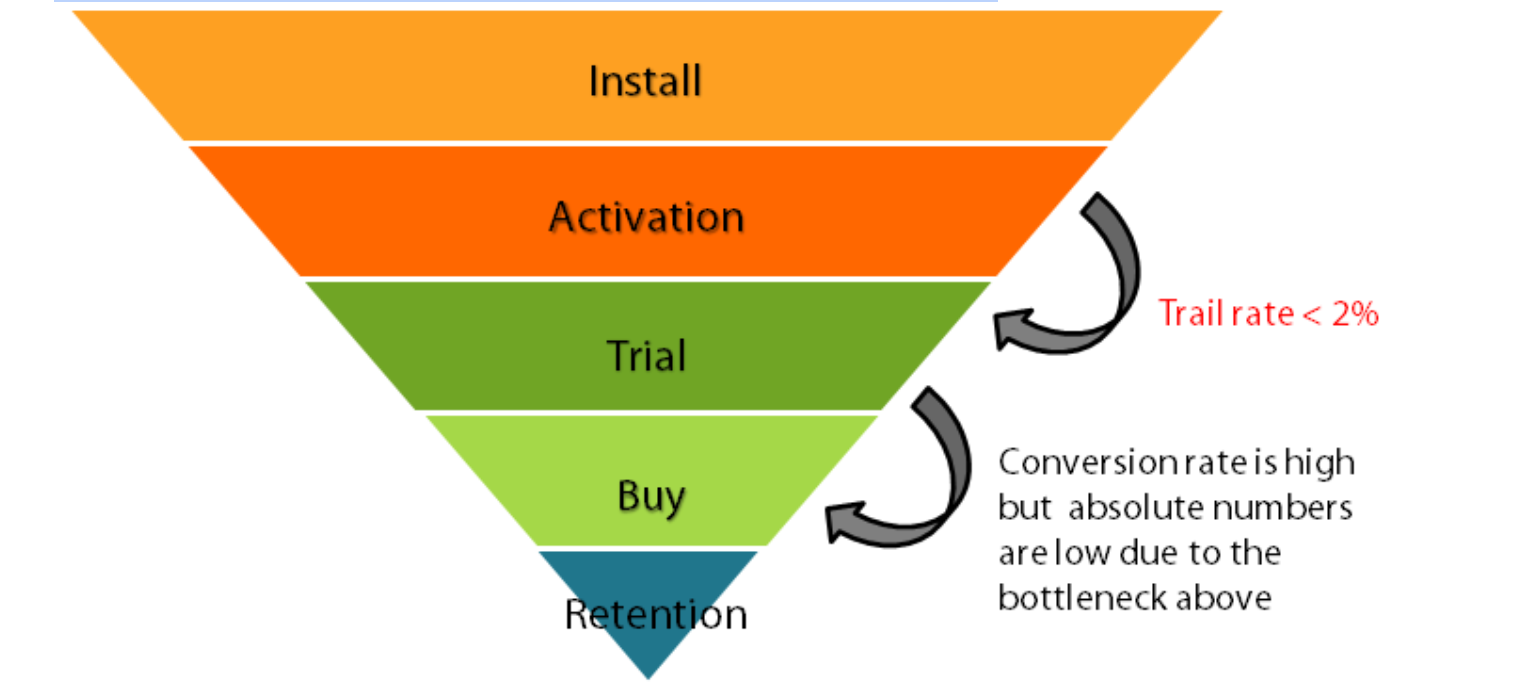
Our job was to help solve this problem.
Start with BADIR
We started with the BADIR framework. Data science projects’ success often depends on how it is shaped from the beginning, and the BADIR framework helped us ensure all the stakeholders were aligned.
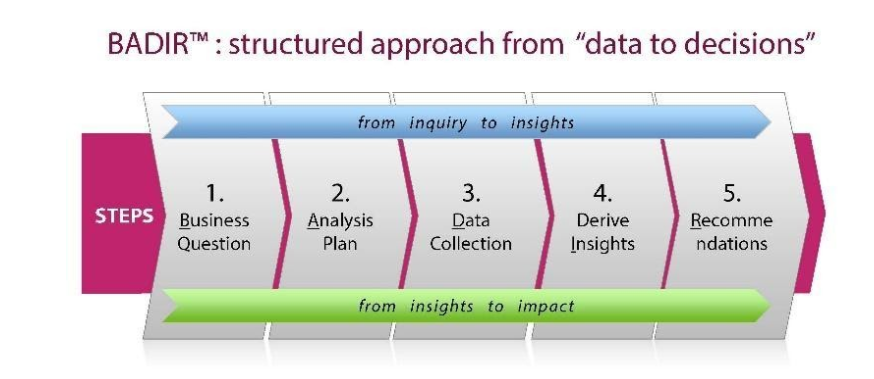
Once the business Question was formed, the Analysis Plan was designed along with the stakeholders, i.e., the product and the marketing teams from the client side. The data extraction took quite some time due to the complexity of the information-rich features we were trying to pull from the database.
Next began our journey to derive insights with the help of Machine learning models.
Feature engineering and added complexity
Any machine learning model can only extract a pattern if it suitably exists in the dataset. This is why feature engineering is such an essential step before using the data to train a model. We did a fair share of brainstorming, too – creating new features out of the existing ones. The new features often have more predictive value than the original ones.
For us, there was an added layer of complexity involved. The users could form small groups, and the whole group could have to go for a trial or paid subscription together. So we realized that understanding customer behavior was not enough; we needed to understand group dynamics. To facilitate this, we engineered features that would give us the group’s behavior based on the users’ behavior within them. These features answered questions such as
- How active was the whole group on average?
- How much did the most active user in the group interact with the group?
- Was there anyone in the group who interacted with certain features at all?
- What fraction of the group members interacted with specific features?
Machine learning model and insights
The next step was to train machine learning models.
To build a predictive model, we have a methodology in place as part of the BADIR framework.(https://aryng.com/aryng-BADIR-advantage)
It starts by pre-processing the data and ends with a tuned ML model. We used gradient boosting trees for the current problem.
Once the machine learning model can predict satisfactorily, we take features that are most important in the prediction and try to zoom in and do a detailed analysis.
One way to understand customers’ detailed breakdown in terms of the important features is to build a single decision tree. This gives us a clearer picture of which group of customers are more likely to try and the distinguishing features.
Once the decision tree was built with satisfactory results, we figured out the impactful and actionable features. It’s the combination that makes any recommendation valuable and useful.
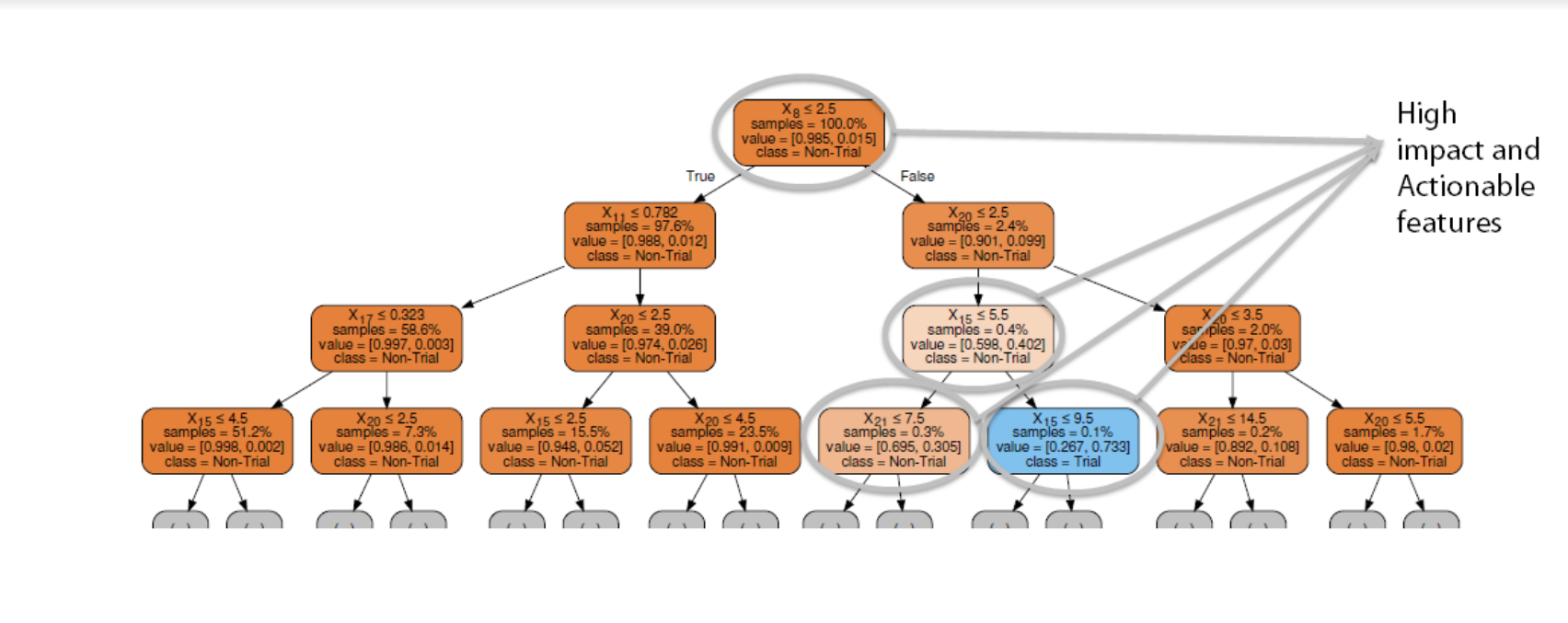
Recommendations
Once the features were finalized, it was time to formulate the recommendations.
We primarily made three recommendations based on our models and inference. Each of the suggestions was to bring in a change in a different feature of the app.
One of our recommendations was to encourage users to add more labels for a particular feature. This would lead to a $2.1M increase in CLV per yearly cohort of users.
We can see the transformation in the following funnel pathway.
| Funnel | Impact estimate |
| New users per year | 2.8M |
| 97% of groups impacted by encouragement to add more labels, and a success rate of 25% | 0.68M |
| Increase in number of groups subscribing for trial with improved (+5.3%) trial rate | 36K |
| Number of groups subscribing for a paid premium subscription | 25K |
| Increase in lifetime value per yearly cohort | $2.1M |
Results of Machine Learning to Increase Propensity of Customers to Subscribe
Together these recommendations would increase the conversion by more than 3x. It would also increase the CLV from yearly cohorts by $2.6 million.
The project was completed within a short period due to our robust BADIR framework, which provided a directed approach from the beginning. It guided our explorations and models towards an actionable outcome and ensured that all the stakeholder’s expectations and needs were met.












